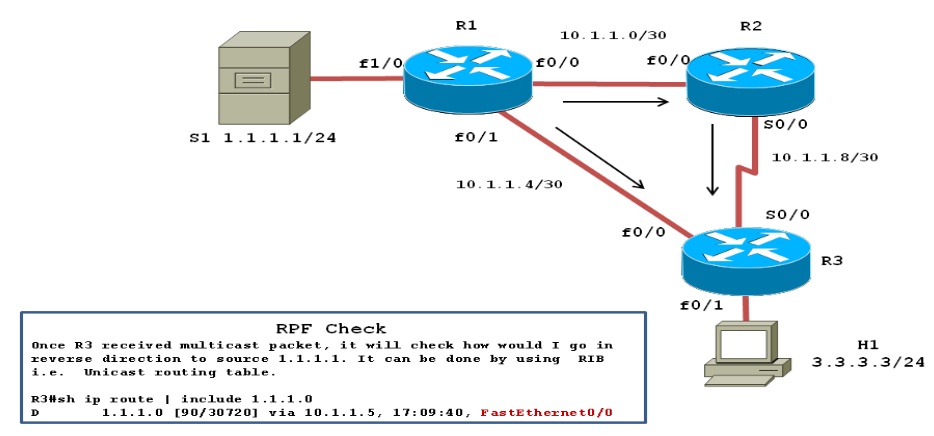
Specifying A Next-Hop IP Address
In order to insert a static default route into the routing table, ip route 0.0.0.0 0.0.0.0 155.0.0.7 is configured.
R9#show ip route
Gateway of last resort is 155.0.0.7 to network 0.0.0.0
S* 0.0.0.0/0 [1/0] via 155.0.0.7
155.0.0.0/16 is variably subnetted, 2 subnets, 2 masks
C 155.0.0.0/24 is directly connected, GigabitEthernet1
L 155.0.0.9/32 is directly connected, GigabitEthernet1
I wrote a simple TCL script to ping the remote destinations at once.
R9#tclsh
R9(tcl)#foreach n {
+>(tcl)#155.1.1.1
+>(tcl)#155.2.2.2
+>(tcl)#155.3.3.3
+>(tcl)#155.4.4.4
+>(tcl)#} { ping $n }
Sending 5, 100-byte ICMP Echos to 155.1.1.1, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 1/1/1 ms
Sending 5, 100-byte ICMP Echos to 155.2.2.2, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 1/1/1 ms
Sending 5, 100-byte ICMP Echos to 155.3.3.3, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 1/1/1 ms
Sending 5, 100-byte ICMP Echos to 155.4.4.4, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 1/1/1 ms
Evidently, the pings are successful, but let’s view the lookup process in more detail.
First, R9 must generate an ARP Request to find the MAC address of its next-hop neighbor R7. The ARP Request contains the following information: src IP = 155.0.0.9, scr MAC = 000c.2999.fcba, dst IP = 155.0.0.7, and dst MAC = 0000.0000.0000 (unknown). R7 sends back an ARP Reply with src IP = 155.0.0.7, src MAC = 000c.2968.22dd, dst IP = 155.0.0.9, and dst MAC = 000c.2999.fcba.
R9#debug arp
IP ARP: sent req src 155.0.0.9 000c.2999.fcba,
dst 155.0.0.7 0000.0000.0000 GigabitEthernet1
IP ARP: rcvd rep src 155.0.0.7 000c.2968.22dd, dst 155.0.0.9 GigabitEthernet1
Notice that the ARP cache contains only a single dynamically learned entry (R7). In fact, this is the only required information, because from R9’s perspective all remote destinations are reached through R7. R9 is effectively saying: “All packets that do not have a more specific entry in the routing table are forwarded to R7, so I will address my Layer 2 frames to him accordingly.”
R9#show arp
Protocol Address Age (min) Hardware Addr Type Interface
Internet 155.0.0.7 0 000c.2968.22dd ARPA GigabitEthernet1
Internet 155.0.0.9 - 000c.2999.fcba ARPA GigabitEthernet1
Specifying An Exit Interface
The previous chapter proved that pointing a static default route to a next-hop IP is an effective solution, requiring minimal memory resources and processing cycles to reconstruct the Layer 2 header. By contrast, pointing a route to an exit interface can potentially cause high processor utilization and a very large ARP cache (along with attendant memory allocation failures).
R9(config)#ip route 0.0.0.0 0.0.0.0 GigabitEthernet1
When a static route is associated with an exit interface, it shows up in the routing table as directly connected.
R9#show ip route
Gateway of last resort is 0.0.0.0 to network 0.0.0.0
S* 0.0.0.0/0 is directly connected, GigabitEthernet1
155.0.0.0/16 is variably subnetted, 2 subnets, 2 masks
C 155.0.0.0/24 is directly connected, GigabitEthernet1
L 155.0.0.9/32 is directly connected, GigabitEthernet1
Now, directly connected implies Layer 2 neighborship, which causes the router to consider each destination within the range of the route to be directly reached through that interface. So, instead of resolving to a
single next-hop IP address, the router must find the Layer 2 information for each unique destination.
If I issued the TCL script again, the pings would continue to fly successfully (omitting the lengthy output, you’ll just have to believe me). But what happens under the hood? The router is generating ARP requests for all destinations separately.
R7#debug arp
IP ARP: rcvd req src 155.0.0.9 000c.2999.fcba, dst 155.1.1.1 GigabitEthernet1
IP ARP: rcvd req src 155.0.0.9 000c.2999.fcba, dst 155.2.2.2 GigabitEthernet1
IP ARP: rcvd req src 155.0.0.9 000c.2999.fcba, dst 155.3.3.3 GigabitEthernet1
IP ARP: rcvd req src 155.0.0.9 000c.2999.fcba, dst 155.4.4.4 GigabitEthernet1
Wait.. If the router sends an ARP request for the final destination, which is not actually directly connected, then how does the packet reach its intended recipient? Simple: proxy ARP. Today, the use of proxy ARP is not that common. In fact, it is often a "quick fix" for potential routing issues. Proxy ARP uses the exact same process as ARP, except the ARP request is requesting a MAC address that is not on the local subnet. If a router has a route to the requested destination, it can issue a proxy ARP reply with its own MAC address on behalf of the target host. The following figure demonstrates the concept.
Notice that R7 replies to the received ARP requests by sending back its interface GigabitEthernet1 MAC address.
R7#show interface GigabitEthernet1
GigabitEthernet1 is up, line protocol is up
Hardware is CSR vNIC, address is 000c.2968.22dd (bia 000c.2968.22dd)
Internet address is 155.0.0.7/24
R7#debug arp
IP ARP: sent rep src 155.1.1.1 000c.2968.22dd,
dst 155.0.0.9 000c.2999.fcba GigabitEthernet1
IP ARP: sent rep src 155.2.2.2 000c.2968.22dd,
dst 155.0.0.9 000c.2999.fcba GigabitEthernet1
IP ARP: sent rep src 155.3.3.3 000c.2968.22dd,
dst 155.0.0.9 000c.2999.fcba GigabitEthernet1
IP ARP: sent rep src 155.4.4.4 000c.2968.22dd,
dst 155.0.0.9 000c.2999.fcba GigabitEthernet1
R7#show ip interface GigabitEthernet1
GigabitEthernet1 is up, line protocol is up
Internet address is 155.0.0.7/24
Broadcast address is 255.255.255.255
Proxy ARP is enabled
The ARP cache on R9 has grown considerably larger. Also notice that all entries are essentially identical, mapped to the same hardware address. In a lab environment, these effects of a larger ARP table and higher CPU utilization are minimal but in a high-volume production network potentially devastating consequences may result.
R9#show arp
Protocol Address Age (min) Hardware Addr Type Interface
Internet 155.1.1.1 0 000c.2968.22dd ARPA GigabitEthernet1
Internet 155.2.2.2 0 000c.2968.22dd ARPA GigabitEthernet1
Internet 155.3.3.3 0 000c.2968.22dd ARPA GigabitEthernet1
Internet 155.4.4.4 0 000c.2968.22dd ARPA GigabitEthernet1
As another important consideration, the operation is completely reliant on the proxy ARP feature on the neighboring router. If proxy ARP is disabled, the destination IP address can no longer be resolved to a MAC address. The result is an incomplete ARP entry due to no ARP reply being received for an ARP request that was sent out. Therefore, the Layer 2 header cannot be built, and the packet is dropped.
Source: cisco.com